It was late, one last review before bed, and I was watching two agents talk to each other about my plan.
The research-planner had just finished. 85,000 tokens, three and a half minutes of reading code, asking me clarifying questions, weighing tradeoffs, writing a structured plan to disk. It handed off with a signal: READY FOR REVIEW. The orchestrator picked it up, read the plan, and said something I hadn't told it to say: "Good plan. Let me get it reviewed before we start implementing."
Then the plan-reviewer launched. Cyan label in the terminal. It started reading migration files, searching for patterns in the executor, pulling in auth dependencies. Twenty-four tool uses. Four minutes and forty-four seconds. I sat there in the glow of the terminal, Twinings mint tea long cold, watching an agent wear three different hats (engineer, test engineer, reliability engineer) and critique the plan I'd written with the planner just minutes earlier.
It found things. Not trivial things. Assumptions about API contracts that hadn't been validated against the actual library. An edge case in the state machine where an empty graph would silently succeed instead of failing with a clear error. A migration that couldn't be rolled back cleanly. The reviewer flagged each one with a severity, a concrete risk scenario, and a specific fix. Then it rendered its verdict: REVISE.
The planner came back. Addressed the findings. Revised the plan. The reviewer ran again. This time: APPROVE.
No code had been written yet… and the most expensive mistakes had already been caught.
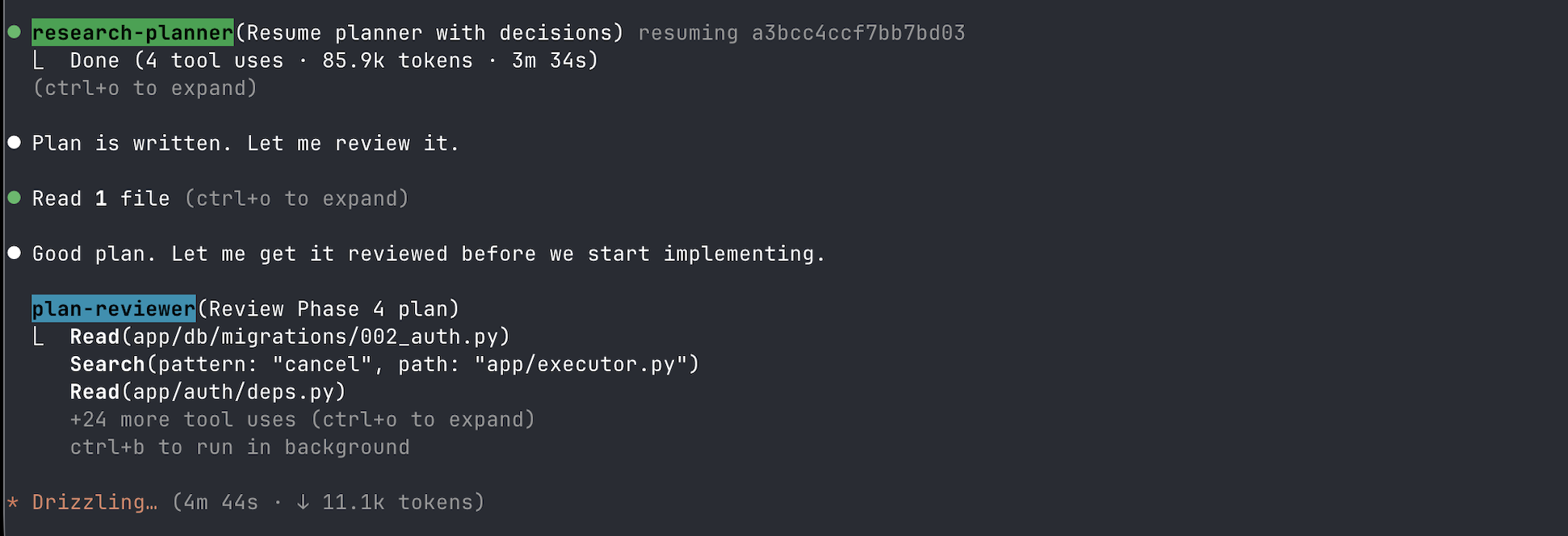
The research-planner finishes, the orchestrator reviews, then launches the plan-reviewer. Twenty-four tool uses, four minutes and forty-four seconds.
attention as currency
I expected the loop to catch bugs. It did. But what I didn't expect was how it changed where my attention went. Attention is the currency that matters, mine and the model's. The context window is the agent's attention budget. My cognitive load is mine. The loop protects both. The reviewer catches the things I'd otherwise spend an afternoon catching myself, and those hours come back as space to think about architecture, user experience, scope. The things that only I can decide.
I've written about planning as leverage, and about letting go once the plan is good enough. Both of those posts treated planning as a human activity, with AI as the execution layer. What happened that night was different. The quality gate was automated. Not in a CI pipeline sense, where the machine checks whether the code compiles or the tests pass. An agent with the full context of the codebase and three distinct review lenses was scrutinizing whether the design actually holds up before anyone touched an editor.
That's the loop: plan, review, revise, approve, implement.
It sounds simple. It is simple. But it changed everything about how I build software with agents.
what a planner agent actually does
The research-planner is a structured dialogue partner with specific behaviors encoded into its agent definition. GraphWeave is a side project I've been building to explore agent orchestration and learn LangGraph. From its research-planner:
Before proposing a solution, identify 2-3 key assumptions and ask me to confirm them. For non-trivial decisions, present 2-3 options as a table: approach | tradeoffs | risk | mitigation. Default to the simplest approach unless I indicate otherwise. Flag irreversible decisions explicitly.
It reads the existing code first. It checks library documentation. It cross-references project constraints. It verifies file paths and APIs against the actual codebase rather than guessing. And when it writes the plan, it writes it to a specific location (.claude/gw-plans/) with a specific structure: architecture diagrams, decisions and risks, a commit plan where each commit is independently buildable, and a detailed todolist granular enough that another agent can follow it mechanically.
The plan is an executable specification, and the planner knows it can't review its own work:
READY FOR REVIEW: .claude/gw-plans/path/to/plan.md
That handoff line is the hinge of the whole system. Getting it right took longer than I expected. Early versions had the planner spawning its own reviewer, which is about as useful as grading your own homework. The separation had to be structural, not suggested. The planner ends its turn. The orchestrator decides what happens next.
how plans are organized
The plan format evolved through trial and error into something I didn't expect to care about this much: a structure optimized for attention, mine and the model's, and quite different from where I started.
A large feature gets an overview file and a set of part files, one per commit boundary. GraphWeave's canvas phase 1 looks like this:
phase-1-canvas-core/
overview.md — architecture, decisions, scope, risks
phase-1.1-test-infra-ui-base.md — commit plan + detailed todolist
phase-1.2-node-components.md — commit plan + detailed todolist
phase-1.3-graph-canvas.md — commit plan + detailed todolist
phase-1.4-config-panel.md — commit plan + detailed todolist
phase-1.5-save-load.md — commit plan + detailed todolist
phase-1.6-floating-toolbar.md — commit plan + detailed todolist
The overview is the what and why: ASCII architecture diagrams, layer boundaries, engineering decisions as tables with alternatives considered, an explicit "Out of Scope" section to prevent scope creep. It gets reviewed once. The part files are the how: each one scoped to a single commit, with the exact files to create or modify, a granular todolist, and the tests that verify it. Each part is independently buildable. If part 1.3 breaks, parts 1.1 and 1.2 still stand on their own.
This structure serves the reviewer agent as much as it serves me. When the plan-reviewer runs its three passes, it's loading the overview plus whatever part files are relevant. If the whole plan were a single 2,000-line document, the reviewer would be working at the edges of its attention span, the same way I'd lose focus reading a 2,000-line spec late at night. I learned this the hard way. The first monolithic plan I sent through review came back with findings that contradicted things stated clearly on page one. The model wasn't ignoring the plan. It was losing track of it. Same thing that happens to me when a spec sprawls past the point where I can hold the whole shape in my head.
My rule of thumb: keep plan files between 350-500 lines. Dense enough to be self-contained, where someone reading only that file understands what to build and why. Short enough that the model's attention doesn't degrade into hallucination. The overview can push toward 500 lines because it's architecture-heavy with diagrams and decision tables. Part files aim for 350-400 because they're implementation-focused and need precision.
Every token in the context window is a claim on the model's attention. Waste tokens on sprawl, and the model starts making its own decisions about what to ignore. The plan structure is attention management. For the reviewer, for the implementer, and for me.
what a reviewer agent actually does
The plan-reviewer runs three sequential passes. Every plan goes through all three. All must approve before implementation begins. I didn't arrive at three passes through any grand design. The first version was a single freeform review, and the output was thorough but scattered. Findings about test coverage sat next to findings about rollback strategy, and I couldn't tell which ones actually mattered. Splitting the review into passes gave each one a focus, and gave me a way to read the output without my eyes glazing over.
The first pass is senior engineer: architecture and design. API contract correctness: does the plan actually match the library's real signatures, or is it hallucinating an API that doesn't exist? Error handling, security boundaries, over-engineering. The reviewer checks the plan against the actual codebase, not against what the planner claims the codebase looks like.
The second pass is SDET: test coverage and regression prevention. The reviewer maps every core flow in the plan to the tests that would catch a regression. Where there's a gap, it flags the specific test to add, what it should assert, and its priority.
The third pass is reliability engineer: failure mode analysis, behavioral regressions, rollback strategy. Can the change be reverted cleanly, or are there schema migrations that make rollback dangerous? What's the blast radius? Frontend-only, or does it touch shared utilities? Each risk gets a likelihood, impact, mitigation, and detection strategy.
Every finding follows a format: what's wrong, why it matters (a concrete scenario), how to fix it, and what breaks if you skip it. Findings are rated BLOCKER, IMPORTANT, or SUGGESTION. Any blocker means the verdict is REVISE. The reviewer never modifies the plan. It reports. The planner fixes. The loop continues until the verdict is APPROVE.
what this looks like in practice
Here's what I saw in my terminal that night. The orchestrator routing between agents, each one labeled and color-coded.
The research-planner finishes its work: reading code, asking me questions, writing the plan. The orchestrator reads the output, sees it's a plan, and routes it to the reviewer without being told. The plan-reviewer launches, pulls in twenty-four files across the codebase, runs all three passes, and delivers a verdict.
After the plan is approved, implementation happens. And when it's done, another loop kicks in. The idea for parallel review agents traces back to our hackathon in November. Mark, my manager, was building a Claude Code clone to learn more about LLM internals and terminal rendering. I was hacking on dev-agent. At some point he stitched together agents running in parallel, and I remember the wow moment — watching multiple streams of work happen at once, each one independent but converging on the same output. It took me quite a while to finally incorporate that into my own workflow, but now the code-reviewer orchestrates three specialized agents in parallel: security-reviewer (auth, ownership, secrets, injection), logic-reviewer (correctness, edge cases, race conditions), and quality-reviewer (tests, conventions, readability). Three agents, same diff, running simultaneously. They report back, findings get deduplicated, and a unified verdict drops: APPROVE, REQUEST CHANGES, or NEEDS DISCUSSION.

Security (red), logic (yellow), and quality (blue), all running in the background on the same diff.
The whole flow: plan, plan-review, implement, code-review, PR. Two quality gates, both automated, both grounded in the actual codebase. No code gets written before the design passes scrutiny. No PR gets opened before the code passes scrutiny.
why this works
The first time I tried something like this, it was clumsy. One agent doing everything: planning, reviewing, implementing. The output was mediocre because the agent had no tension. It was reviewing its own work, which is about as effective as proofreading your own email right after you write it.
So I split the roles. Separation of concerns, applied to agents. The planner's job is to propose. The reviewer's job is to challenge. They have different system prompts, different review criteria, different incentive structures. The planner is optimized for completeness and clarity. The reviewer is optimized for finding holes. They're adversarial the same way a code review is adversarial. That friction is the whole point.
I built GraphWeave partly to learn more about this kind of orchestration. It's a visual LangGraph builder. You draw a graph on a canvas and the graph runs exactly as drawn. Start node, LLM node, tool nodes, condition branches, human-in-the-loop pauses. What you draw is what executes, streamed back in real time over SSE.
What you draw is what runs. Start → LLM → End, streamed back in real time.
the compounding effect
This system evolved across three projects over several months. Each iteration taught me something, though not always what I expected.
The first version had too many agents. Fourteen specialized roles with an orchestrator routing between them. It worked, but quite a bit of my time went to coordinating agents rather than thinking about the actual problem (which, if you think about it, is the same tax I was trying to eliminate). Some agents existed because I thought I'd need them, and the work never demanded them.
The second version streamlined the pattern. Fewer agents, clearer boundaries. The plan-reviewer became more structured, with three named passes instead of a freeform review. The code-reviewer learned to run its sub-agents in parallel instead of sequentially. And the plan format itself evolved from monolithic documents into the phased structure I described earlier: overviews and parts, each file dense enough to be self-contained, short enough to stay within the model's reliable attention window. That structural change alone made the reviewer's output quite a bit sharper. Same agent, same prompts, better input shape.
The third version stripped it further. The essential loop (planner, reviewer, implementer, code reviewer, PR composer) emerged as the irreducible core. Everything else was decoration.
Looking back, the thing that actually compounded wasn't the agents or the prompts. It was the boundaries between them. Each iteration made those cleaner: what the planner produces, what the reviewer expects, what the implementer needs. When those boundaries are precise and the handoff artifacts are dense, the agents operate with surprising autonomy. When they're vague, you spend more time managing agents than thinking about the problem.
what I actually learned
The loop taught me something I didn't expect to learn from tooling.
The reviewer makes the planner better over time, because I learn. I see what the reviewer catches, I internalize those patterns, and my next prompt to the planner is more precise. The reviewer kept flagging rollback risks in my early plans, and after the third or fourth time I started writing rollback sections before the planner even asked. The reviewer caught test coverage gaps in integration boundaries, and now I structure plans so those boundaries are explicit from the start. The loop made me better at planning, which made the planner better at planning, which gave the reviewer less to catch. The system tightens… and the attention it frees up is the whole point.
the plan is still mine
I want to be precise about what's happening here, because it would be easy to read this as "AI plans and reviews my work for me." That's not it.
The plan starts with my intent. The planner helps me articulate it, challenges my assumptions, presents options I haven't considered. The decisions are mine: which approach to take, which tradeoffs to accept, which scope to cut. The reviewer pokes holes in the plan. It's checking whether the plan, as written, will actually work when someone tries to implement it. Whether the APIs exist. Whether the tests cover the core flows. Whether the migration can be rolled back.
The loop extends my judgment's reach. I can make decisions at a higher altitude because the lower-altitude verification is handled. I'm thinking about architecture while the reviewer is checking API signatures. I'm thinking about user experience while the SDET pass is mapping test coverage. The cognitive budget I wrote about in Planning as Leverage, the finite attention I have each day, gets spent on the decisions that only I can make.
It was late, one last review before bed, and I was watching agents debate the merits of my rollback strategy. For the first time in a long time, I was leaning back. Just watching the system work.
The plan was still mine — the rigor was automated.